多语言踩坑汇总

土耳其语大小写转换
土耳其语的大小写转换规则与英语(及大多数拉丁字母语言)存在显著差异,这在计算机科学界被称为“土耳其语 I 问题”,其实还有阿塞拜疆语也有这个问题。
1. 核心差异:有点与无点的“I”
在英语中,字母 i 的大写是 I。但在土耳其语中,这两个字母分别属于两组不同的对应关系 :
有点字母组:小写 i 对应大写 İ(带点的 I)。
无点字母组:小写 ı(无点 i)对应大写 I(无点 I)。
这意味着:
在英语环境下:
i↔I在土耳其语环境下:
i↔İ以及ı↔I
2. 技术与软件开发中的问题
由于许多编程语言(如 C#、Java等)的字符串转换函数(如 toLowerCase() 或 toUpperCase())在默认情况下会参考系统的本地化设置(Locale),这导致了大量的软件缺陷 :
关键字失效:如果一个编译器或解析器在土耳其语环境下运行,将大写的英文单词 “INFO” 转换为小写,结果会变成 “ınfo”(使用无点 ı),而不是预期的 “info”。这会导致程序无法识别指令或配置 。
标签损坏:在游戏引擎(如 Unreal Engine)中,如果对包含富文本标签的代码进行文化敏感的大小写转换,
<img id="...">可能会变成<İMG İD="...">,导致系统无法识别标签。文件系统错误:如果文件名包含 “I”,在土耳其语环境下转换为小写后,可能因为字符不匹配而导致无法找到文件
3. 历史与设计原因
Unicode 设计:Unicode 为了保持与早期字符集(如 ISO-8859-9)的兼容性,将土耳其语的无点大写 I 与英语的大写 I 统一使用了同一个码点(U+0049),这使得大小写转换必须依赖于语言上下文(Locale)才能正确执行 。
语言改革:土耳其语在 20 世纪 20 年代拉丁化改革时,为了实现“一个字母对应一个声音”的原则,特意区分了这两种元音 。
4. 解决方案
为了避免这类 Bug,当需要将字符串转换为统一的大小写以便后续处理(如比较或存储)时,不应直接使用 ToUpper() 或 ToLower(),因为它们默认使用系统的当前文化设置(CurrentCulture)。
- 推荐方案:使用
String.ToUpperInvariant()或String.ToLowerInvariant()
浮点数转换字符串小数点.变成,
在许多欧洲国家或地区的语言设置中,默认的数字小数点分隔符是逗号(,)而不是点(.)。在执行 ToString() 操作时,.NET 会根据当前线程的文化环境自动选择分隔符。
解决方法
使用固定文化(CultureInfo.InvariantCulture)
InvariantCulture 的默认小数点分隔符始终是 .,且不会随系统语言环境的变化而改变
1 | double value = 1.5; |
Application.systemLanguage返回语言标识错误
一些语言在调用Application.systemLanguage查询时会被错误的认为成马来语
解决方法
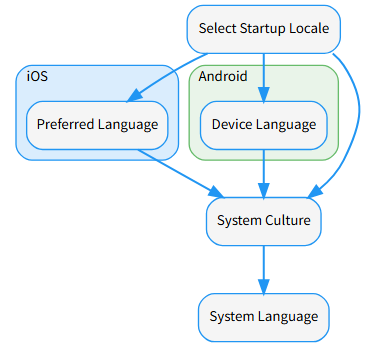
iOS - Preferred Language: 使用 iOS Preferred Language
- 根据 iOS 本地化指南,用户的
preferredLanguages是在 iOS 设置(设置 ➞ 通用 ➞ 语言与地区)中列出的语言顺序,项目中只取第一个即可。
- 根据 iOS 本地化指南,用户的
1 | [] |
1 | extern "C" |
- Android - Device Language: 使用 Android getDefault
1 | static string GetAndroidDeviceLanguage() |
- System Culture: 使用 CultureInfo.CurrentUICulture
1 | CultureInfo.CurrentUICulture.TwoLetterISOLanguageName |
- System Language: 使用 SystemLanguage 做为最终检查
1 | Application.systemLanguage |
阿拉伯语处理
Tashkeel (发音/变音符号)
Tashkeel(阿拉伯语:تشكيل)是指阿拉伯语中的变音符号或发音符号。由于阿拉伯字母主要是辅音,Tashkeel 符号被添加在字母的上方或下方,用以指示短元音、音节重复或静音。
常见类型:包括 Fathah (开口符)、Kasrah (齐齿符)、Dammah (合口符)、Sukun (静符)、Shadda (叠音符) 等。
作用:这些符号对于准确的读音和理解句意至关重要。在普通的现代阿拉伯语出版物中,Tashkeel 有时会被省略,但在宗教文献(如古兰经)、诗歌和初级语言教材中是必须显示的。
Unity 开发中的挑战:并非所有字体都能完美支持这些符号的渲染。在使用
Arabic Support for Unity插件时,开发者可以选择显示或隐藏这些符号。
Hindu numbers (印地数字 / 东阿拉伯数字)
在 Unity 插件(如 ArabicSupport)的语境下,Hindu numbers 指的是东阿拉伯数字(Eastern Arabic numerals),即在阿拉伯语、波斯语和乌尔都语地区广泛使用的数字形状 。
数字形态:它们看起来像这样:٠ ١ ٢ ٣ ٤ ٥ ٦ ٧ ٨ ٩ 。
命名困惑:
我们平时用的 0, 1, 2… 在国际上被称为“西阿拉伯数字”(Western Arabic numerals)。
插件中提到的 Hindu numbers 其实是指在阿拉伯语国家常见的“东阿拉伯数字”。
Unity 开发中的功能:
- 自动转换:
Arabic Support for Unity插件提供选项,可以将标准英文字符(0-9)自动转换为这种特定的数字形状。
- 自动转换:
1 | using UnityEngine; |
CJK 字体缺失
中文等东亚字符显示为方块(□)的主要原因是字体文件不包含 CJK(中日韩)字符集,或者 TextMeshPro (TMP) 的字体资产(Font Asset)未包含对应字符的位图信息。
选择支持 CJK 的字体
建议将 Atlas Resolution 设置为 2048x2048 或 4096x4096,因为中文等东亚字符数量巨大,需要更大的贴图空间
对于聊天系统等无法预知内容的文本,可以使用代码在运行时动态添加字符到字体资产中(如使用
chineseFont.TryAddCharacters(c))并强制更新